最新研究 Raspberry Pi 4のGPUプログラミング
32GFLOPSの高速積和演算プロセッサを動かしてみよう
- 著者・講師:杉崎 優
- 企画・編集:ZEPエンジニアリング株式会社
- 関連製品:[VOD/Pi3A KIT]ラズパイ・キットで学ぶLinux I/Oボードの作り方・探し方・動かし方
- 関連製品:[VOD/PiZero KIT]Python×ラズパイで初めての量子コンピュータ
- 関連製品:[VOD/Pi KIT] ラズベリー・パイで学ぶLinux&Pythonプログラミング超入門
- 関連製品:[VOD/KIT] ラズベリー・パイで学ぶエッジAIプログラミング入門
- 関連製品:[VOD/Pi400 KIT] SLAMロボット&ラズパイ付き!ROSプログラミング超入門
- 関連製品:[VOD/Pi KIT] ラズパイ×Pythonで動かして学ぶモータ制御入門
Raspberry Pi 4 の発売
本稿では,Raspberry PiのGPUである“QPU”(Quad Procesing Unit)に焦点を当てます.
“Raspberry Pi”(図1)は,名刺サイズのLinuxコンピュータです.

|
|---|
| 図1 ラズベリー・パイ4 |
ARM CPUやBroadcomのGPU,USBや有線LAN,無線LAN,HDMI,GPIOを搭載しており,低価格かつ低消費電力です.販売数も多く,IoT分野で活発に利用されています.
Raspberry Piのバージョン1が発売開始されたのは2012年のことです.これをはじめとして,Raspberry Piは製品の幅を広げていきました.
名刺よりも小さなサイズの“Raspberry Pi Zero”はたったの5ドルです.また,コネクタ類がいっさいなく,拡張ボードに挿し込みやすい形状の“Raspberry Pi Compute Module”は,工業用の組み込みシステムに利用されています.2019年6月には,“Raspberry Pi 4”の発売がアナウンスされました.
次のように,どのRaspberry Piも,VideoCoreという名称のGPU(Broadcomが開発)を搭載しており,Raspberry Pi 4で一新されました.
- Raspberry Pi 1 (BCM2835): VideoCore IV (4)
- Raspberry Pi 2 (BCM2836): VideoCore IV (4)
- Raspberry Pi 3 (BCM2837): VideoCore IV (4)
- Raspberry Pi 4 (BCM2711): VideoCore VI (6)
CPUとGPUの役割
Raspberry Piの電源を入れると,最終的にLinuxカーネルが起動し,ログイン・プロンプトが表示されます.ここで起動しているのはCPUです.QPUはブラウザやゲームなどを含むグラフィックを描画するために使用されています.
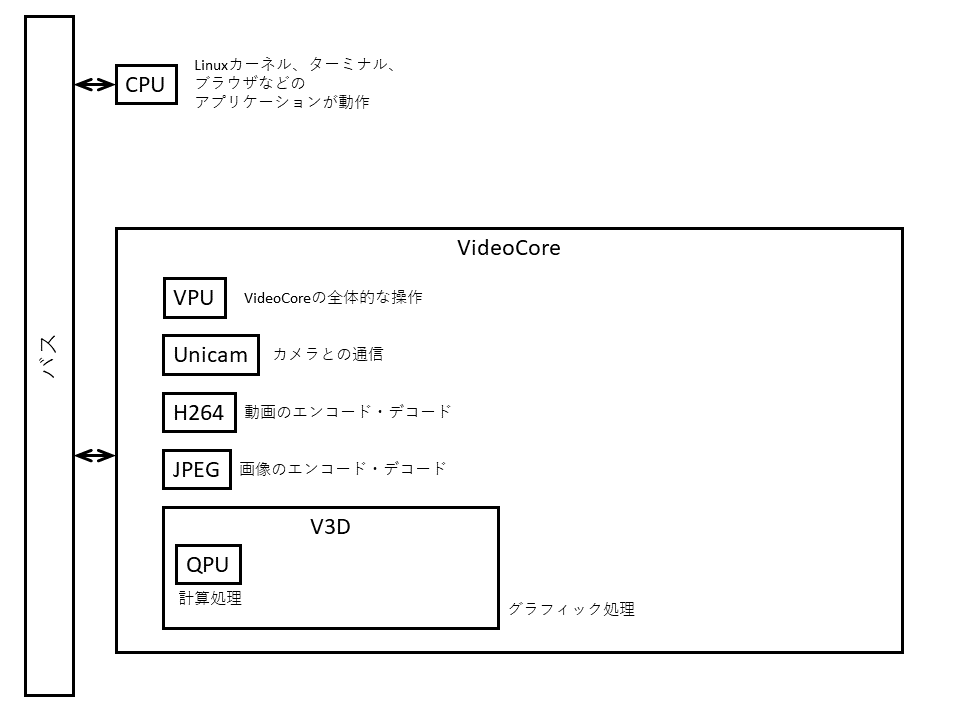
図2に示すのは,Raspberry Pi 4の構造です.Raspberry Pi 4のSoCの中には,大まかにCPUとVideoCoreがあります.
|
|---|
| 図2 Raspberry Pi 4のアーキテクチャ |
CPUは,Linuxカーネルを動かしたり,インターネット通信をしたりするなど,汎用的な処理が行われています.一方VideoCoreは,システムの起動やカメラとの通信,動画や静止画の処理など,低レベルな処理を担当します.VideoCoreの中には,OpenGLなどのグラフィック処理を行うためのV3D(Video 3D)というブロックがあります.そして,V3Dの中で計算処理を担当しているのがQPUです.
コラム1 紛らわしいSoCの名称
Raspberry Pi 1のSoC (system on a chip)のことをBCM2835と呼ぶ人がいたり,かたやBCM2708と呼ぶ人もいたりします.どちらが正しいのでしょうか?Raspberry Piのソフトウェアを開発しているDom Cobley (popcornmix)氏によると,BCM2708はシリーズ名,BCM2835は特定のSoC実装を指すそうです.よって,Raspberry Pi 1のSoCは正しくは「BCM2708ファミリのBCM2835」と呼びます.
同時に動く4つの演算器
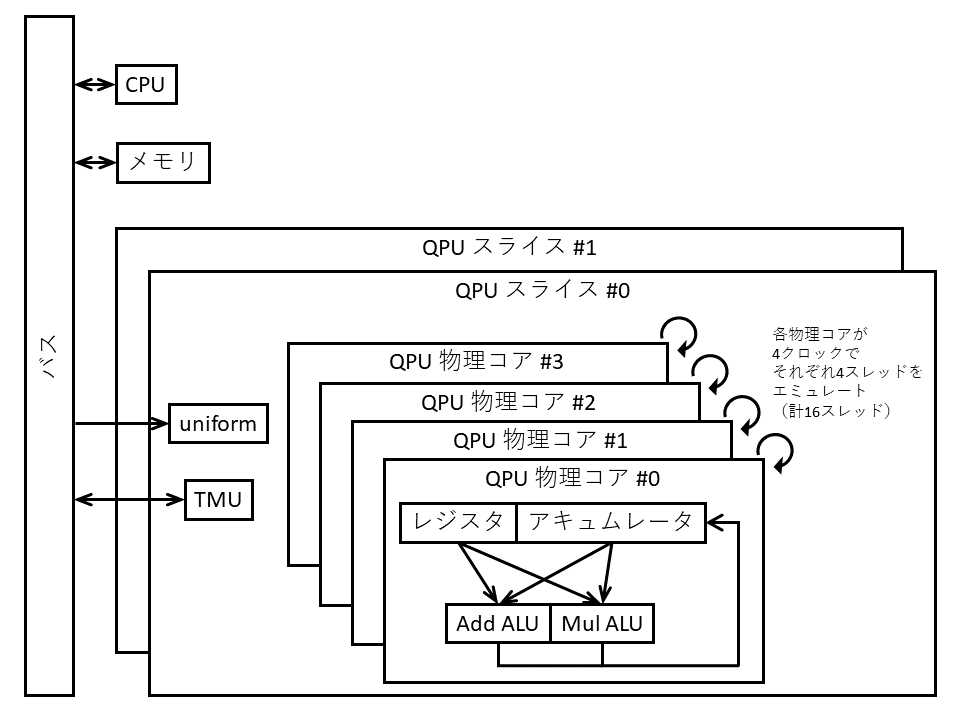
図3に示すのは,Raspberry Pi 4のGPU“QPU”の構造です.
|
|---|
| 図3 Raspberry Pi 4のGPU“QPU”の構造 |
1つのQPUは,4つの物理コアをもち,1つの物理コアには32ビットのALU(計算ユニット)が2つあります.
1つがadd ALU(加算用ALU)で,他方がmul ALU(乗算用ALU)です.2つのALUは同時に動作するため,1命令で2回の計算を行うことができます.
1つの物理コアは,4つの論理スレッドを1クロックごとに切り替えながらエミュレートします.つまり,1つのQPUでは,4クロック単位で16個のスレッドが同時に走っているということです.また,QPUはVideoCoreに複数個搭載されています.4つのQPUのまとまりをスライスと呼びます.VideoCore IVには3つ,VideoCore VIには2つのスライスがあります(図4).

|
|---|
| 図4 ラズベリー・パイの種類 |
Piの世代とGPUの性能
Raspberry PiのGPU VideoCore QPUの理論性能について考えます.
Raspberry Pi 1のQPUは250MHz,Raspberry Pi Zero/2/3のQPUは,300MHz,Raspberry Pi 4のQPUは500MHzで動作するため,QPUの単精度(32ビット)浮動小数点数演算の理論性能は下記に示すとおりです.FLOP/sは,FLoating point number Operations Per secondの略です.
Raspberry Pi 1
- QPU 1個当たりの性能:2 GFLOP/s(= 250 MHz × 4 物理コア × 2 ALU)
- 全QPUの性能:24 GFLOP/s(= 2 GFLOP/s × 4 QPU × 3 スライス)
Raspberry Pi Zero/2/3
- QPU 1個当たりの性能:2.4 GFLOP/s(= 300 MHz × 4 物理コア × 2 ALU)
- 全QPUの性能:2.4 GFLOP/s × 4 QPU × 3 スライス = 28.8 GFLOP/s
Raspberry Pi 4
- QPU 1個当たりの性能::4 GFLOP/s(= 500 MHz × 4 物理コア × 2 ALU)
- 全QPUの性能::32 GFLOP/s(= 4 GFLOP/s × 4 QPU × 2 スライス)
以上のように,Raspberry Piの世代が上がるにつれ,QPUの性能も上がってきています.
QPUのプログラミング言語
QPUは,CPUから指令を受けて動作します.
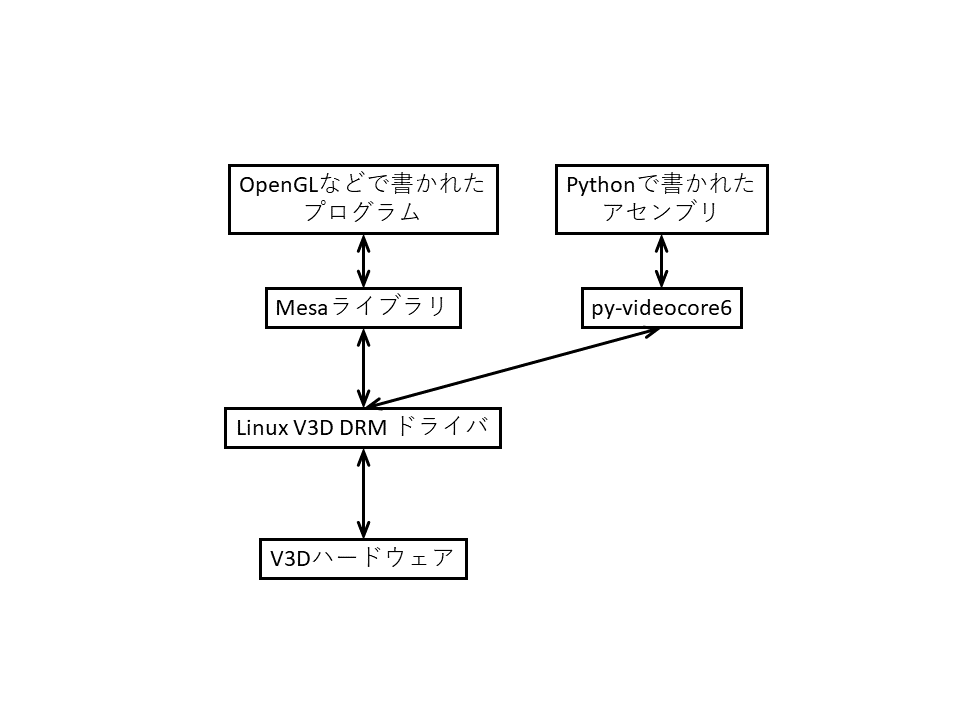
LinuxカーネルのV3D DRM(Direct Rendering Manager)ドライバがV3Dの直接的な操作を担当しています.しかし,QPUは独自の命令セットを採用しているため,OpenGLなどのプログラムはQPU向けにコンパイルした上でV3D DRMドライバに送る必要があります.この処理を担当するのがMesaというライブラリです.
しかし,MesaはOpenGLなどのプログラムは実行できますが,任意のコードをQPUで実行することができません.
そこで,py-videocore6(Idein株式会社)を用います.py-videocore6は,Mesaのコンパイラ部を解析することによって開発された,QPU向けの高級アセンブラです.
図5のように,本来OpenGLなどで書かれていた箇所を,py-videocore6で置き換えることができます.py-videocore6はPython上で動作するので,Pythonの柔軟で豊富な機能やライブラリを用いながら,QPUのプログラムを書くことができます.
|
|---|
| 図5 OpenGLで書かれていた箇所をpy-videocore6で置き換える |
QPU用アセンブラのインストール
Raspbianにpy-videocore6をインストールする手順を示します. Raspbianのインストール方法は
https://www.raspberrypi.org/documentation/installation/installing-images/
などを参照してください.VideoCore VI QPUは現時点ではRaspberry Pi 4にしか搭載されておらず,Raspberry Pi Zero/1/2/3では,py-videocore6を使用できないので注意してください.
以下のコマンドを実行してpy-videocore6をダウンロードします.
|
|---|
| py-videocore6をダウンロード |
ダウンロードできたら cd py-videocore6/ と入力してpy-videocore6のディレクトリに移動してください.次のコマンドを実行することでpy-videocore6をインストールすることができます.
|
|---|
| py-videocore6をインストール |
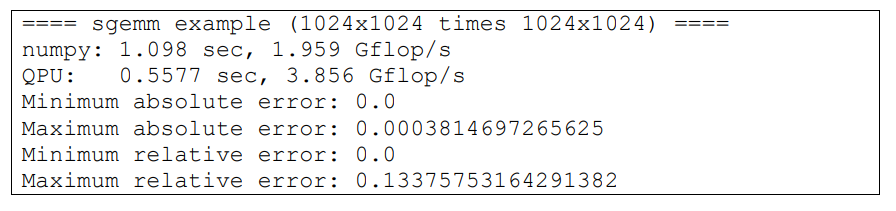
インストールできたら python3 examples/sgemm.py と実行してエラーが出ないか確認してください.このプログラムはQPUで行列の乗算を計算します.正しく実行できたら図6のように表示されます.
|
|---|
| 図6 QPUで行列の乗算 |
QPUの命令セット
QPUには32ビットのALU(計算ユニット)が2つ(add, mul)あります.2つのALUは1命令で同時に動作しますが,実行できる命令が一部異なるので注意が必要です.それぞれのALUで実行できる命令の一部を図7に示します.
|
|---|
| 図7 QPUのALUで実行できる命令 |
例えば,$a = b + c, d = e - f$ という計算を1命令で行いたい場合は add(a, b, c).sub(d, e, f)と書きます.「.」の左側がadd ALU,右側がmul ALUの命令を表しています.左右の命令は省略可能です.省略した場合,自動的にnop 命令(何もしない)が挿入されます.
eidx命令は16個の論理スレッドにおいてそれぞれ0~15の値を返します.tidx命令はQPUの番号(4QPU×2スライスなので0~7)を左に2つシフトした値を返します.つまり,(thread_index >> 2) & 0b1111 がQPUの番号を表します.これらの値はスレッドやQPUごとに別の処理を行わせたいときに便利です.実例は後述します.
QPUのレジスタ
QPUには,5個のアキュムレータr0~r4と64個のレジスタrf0~rf63があります.
レジスタは1命令で2種類までしか読み込めないので注意が必要です.
例えば,add(rf0, rf1, rf2).sub(rf3, rf2, rf1)は可能ですが,add(rf0, rf1, rf2).sub(rf3, rf4, rf5)と書くことはできません.また,アキュムレータは何種類でも読み込めるので,例えば add(rf0, r0, r1).sub(rf1, r2, r3)は可能です.
QPUの即値
命令の引数には即値を指定できます.
即値には -16~15の整数および 1/256,1/128,...,1/2,1.0,2.0,...,128.0 ,つまり$ 2^n (n=-8, -7, …, 6, 7))$の単精度浮動小数点数があります.
即値は1命令で1種類までしか使えません.また,即値を1種類使うと,レジスタを1種類までしか読み込めなくなります(アキュムレータは何種類でも読み込める).例えば add(r0, r1, -16).sub(r2, r3, -16)(r0 = r1 - 16, r2 = r3 + 16)や fadd(rf0, 2.0, rf0).fmul(rf1, rf0, 2.0)(rf0 = 2.0 + rf0, rf1 = 2.0 * rf0)は可能ですが,add(r0, r1, 5).sub(r2, r3, 7)や fadd(rf0, 2.0, rf0).fmul(rf1, 2.0, rf1)と書くことはできません.
QPUパラメータの受け渡し
OpenGLを使ったことのある方は,uniformという名前をご存知かもしれません.uniformは,計算に必要なデータのメモリ・アドレスやパラメータを,GPUでのプログラム実行開始時にCPUからGPUに渡す機能です.
QPUでもuniformを通じてCPUからQPUに32ビット単位で値を渡すことができます.uniformはすべてのQPU・スレッドで同じ値が読み込まれます.uniformをレジスタまたはアキュムレータaに読み込みたい場合は,nop(sig=ldunifrf(a))とします.この命令を実行するたびに内部でアドレスがインクリメントされ,次のuniformの値が読めるようになります.
メモリの読み込みと書き込み
QPUには,TMU(Texture Memory Unit)という,メモリの読み込みと書き込みのためのユニットがあります.
TMUは32ビットの単位でメモリを読み書きします.32ビットのデータをメモリ・アドレスaからレジスタまたはアキュムレータrに読み込みたい場合は,tmuaレジスタにaを書き込んだあと,nop(sig=ldtmu(r))とします.32ビットの値rをメモリ・アドレスaに書き込みたい場合は,tmudレジスタにrを書き込んだあと,tmuaレジスタにaを書き込みます.書き込んだ後は,次の書き込みまでにtmuwt命令を発行し,書き込みの完了を待つ必要があります.
フラグとジャンプ命令
QPUの命令実行においては,計算結果をもとにスレッドごとのフラグをセットすることができます.
フラグはスレッドごとにAとBの2つあり,表に示す条件でセットできます.フラグは基本的にAに格納されますが,add ALUとmul ALUの両方でフラグをセットしようとした場合は,mul ALUのほうの結果はBに格納されます.例えば,加算の結果をもとにフラグAにZフラグ,フラグBにNフラグを立てたい場合はadd(a, b, c, cond=’pushz’).add(a, b, c, cond=’pushn’)とします.
QPUの命令実行においては,計算結果をもとにスレッドごとのフラグをセットすることができます.
フラグはスレッドごとにAとBの2つあり,図8に示す条件でセットできます.

|
|---|
| 図8 フラグの種類とセット条件 |
フラグは基本的にAに格納されますが,add ALUとmul ALUの両方でフラグをセットしようとした場合は,mul ALUのほうの結果はBに格納されます.例えば,加算の結果をもとにフラグAにZフラグ,フラグBにNフラグを立てたい場合はadd(a, b, c, cond=’pushz’).add(a, b, c, cond=’pushn’)とします.
フラグをもとに命令の実行を制御することができます.例えば,add(a, b, c, cond=’ifa’)などです.ifa, ifbはそれぞれフラグA・Bがセットされている場合,ifna, ifnb はそれぞれフラグA・Bがセットされていない場合に命令を実行します.add・mul ALUそれぞれにおいて,push* と if* は片方しか指定することができません.例えば,add(rf0, rf1, rf2, cond=’ifa’).sub(r0, rf1, rf2, cond=’pushz’)といった命令が実行できます.
QPUにはジャンプ命令があります.ジャンプ命令を使用するには,まず飛ぶ先の命令の直前に L.xxx などと書きます.これは,その命令にラベルxxxを付けることを意味します.ラベルの名前は英数字の範囲で自由に設定することができます.この命令にジャンプするには b(R.xxx, cond=yyy)と書きます.yyyには図9に示す条件を指定できます.

|
|---|
| 図9 ジャンプ命令に指定できる条件とその意味 |
意味
ジャンプ命令には3命令の遅延スロットがあります.つまり,cond=yyy の成立・不成立に関わらず,その後の3命令は常に実行されるということです.そのため,ジャンプ命令のあとの3命令に不本意な命令が紛れ込まないよう,注意しましょう.
例として以下に,uniformに指定された値の回数だけループするプログラムを示します.
|
|---|
| uniformに指定された値の回数だけループするプログラム |
上のプログラムのようなループ処理はQPUのプログラムで頻出します.そのため,これをより簡単に書く方法が準備されています.すなわち,L.loop_i を with loop as loop_i: と書き換え,ループの中身をネストします.さらに,b(R.loop_i, cond=’na0’)を loop_i.b(cond=’na0’)と書き換えます.結果として,上のプログラムと同じ動作の以下のプログラムができあがります.
|
|---|
| uniformに指定された値の回数だけループするプログラムを簡単に書く |
以上でQPUの個々の機能の使い方を説明しました.これらをどのように組み合わせればよいか,また,QPUのプログラムをどのように実行すればよいか,このあと確認します.
1つのQPUでHello World!
早速,VideoCore VI QPU向けのプログラムを書いてみましょう.
今回は,長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むというプログラムを考えます.1スレッドで動作することを考えると次の擬似コードになるでしょう.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むというプログラム |
次に,16スレッドで実行することを考えると,次のコードになります.element_indexはスレッドごとの番号(0, 1, ..., 15)を表すとします.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(16スレッドで実行する) |
これを1つのQPUで動作するように書き換えたのが次に示すプログラムwrite_seq.pyです.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッドで実行する) |
上のプログラムを write_seq.py という名前で保存し,以下のコマンドでプログラムを実行してください.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)を実行する} |
すると,図10.pyが出力されるはずです.Test passed! と表示されていればプログラムを正常に実行できています.

|
|---|
| 図10 write_seq.pyの実行結果 |
write_seqメソッドの解説
まず,write_seq メソッドの解説をします.
write_seqは,Pythonでwrite_seq.pyを実行したときに初めに呼び出され,CPUで実行されます.はじめに,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説1 |
としています.これは「py-videocore6の初期化を行い,ドライバのインスタンスをdrvという変数に格納する」という動作になります.
次に,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説2 |
としています.
これは,QPUのプログラムである qpu_write_seq をアセンブルし,それをcodeという変数に格納しています.これをのちにdrv.executeメソッドに渡すことで,QPUでプログラムを実行します.
さらに下で,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説3 |
としています.
これは,32ビット符号なし整数の,長さlengthの配列を確保する処理です.QPUにMMU(Memory Management Unit)がある関係上,QPUからアクセスするメモリはこの drv.alloc メソッドで確保する必要があります.この下の,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説4 |
で配列Aを0で埋めています.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説5 |
で配列Aの中身を表示します.
次にuniformの確保と値の設定を行います.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説6 |
配列の確保には例に漏れず drv.alloc を用います.uniformは32ビット単位で読み込まれるため,配列の要素は32ビット符号なし整数としています.今回は余裕を持たせて配列の長さを1024にしました.uniformの1つ目の要素には配列Aの長さ,2つ目の要素には配列Aの先頭アドレスを設定しています.
そして,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説7 |
で,アセンブルしたQPUのプログラムcodeを,1つのQPUで実行します.ここで,uniformとしてunifの先頭アドレスを指定しています.
qpu_write_seqメソッド
次に,qpu_write_seq メソッドの解説をします.
qpu_write_seq は write_seq メソッド内で drv.program を用いてアセンブルされ,その後 drv.execute を用いてQPUで実行されます.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説8 |
が付いています.
これをデコレータと言います.これはメソッドがQPU専用に書かれており,drv.programでアセンブルされることを想定している,ということを表します.具体的には,addやtmuaなどの名前をメソッド内で使えるようにするのが @qpuデコレータの役割です.
次に
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説9} |
として,レジスタに別名をつけています.これにより,例えば,add(rf0, r0, r1)を add(reg_length, r0, r1)とも書けるようになります.
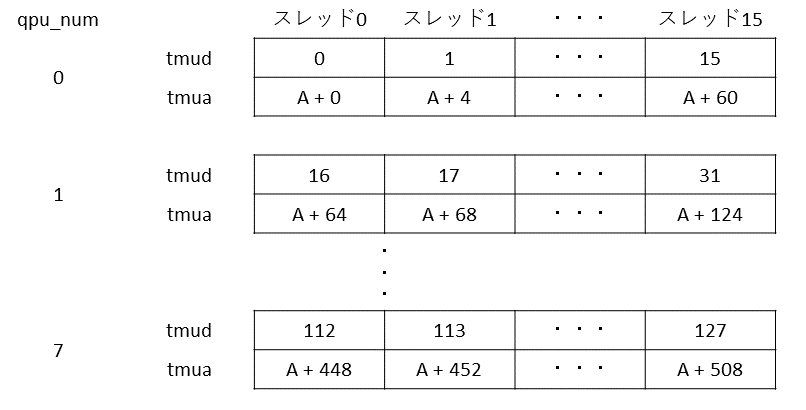
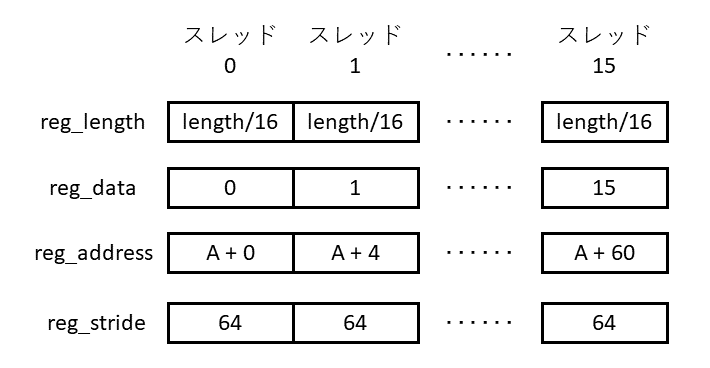
以下,uniformの読み込みと,定数の設定をしています.CPU側では,uniformの1つ目の要素には配列Aの長さ,2つ目の要素には配列Aの先頭アドレスを設定していました.
まず,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説10 |
配列Aの長さをreg_lengthに読み込み,それを16で割っています.この16という数字は,先ほど疑似コードにも示しましたが,QPUが16スレッドで一度に計算やメモリ入出力を行うためです.
次に,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説11 |
配列Aのアドレスをreg_addressに読み込み,それに 4 * element_index を加えています.つまり,スレッド0はreg_address + 0,スレッド1はreg_address + 4,スレッド2はreg_address + 8と,スレッドごとに32ビットずつズレたアドレスを持つことになります.これにより,連続した16個の要素に対する処理を16スレッドで一度に行えるようになります.
次に,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説12} |
reg_strideに64(=4<<4)を設定しています.
strideは歩幅という意味です.今回のプログラムでは,連続した16個の32ビット整数を一度に処理します.つまり,一度に$4 \times 16 = 64$ バイトのデータを処理するということです.すなわち,ループを1回 回るごとにアドレスに64を加算します.かといって64は即値では表現できないので,今回は64という定数をあらかじめ計算し,reg_strideに保持するようにしています.
最後に
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説13 |
で,reg_dataにスレッドの番号を格納しています.以上の処理により,図11に示すレジスタの値が準備できました.
|
|---|
| 図11 reg_dataにスレッドの番号を格納完了 |
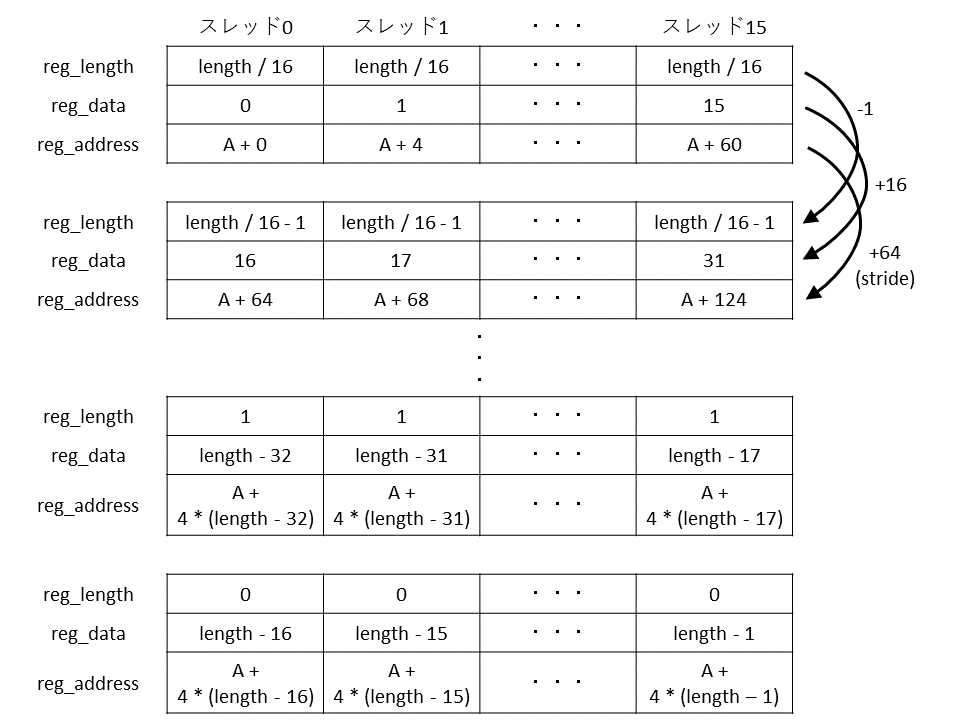
ループ処理
次に,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説14} |
でループを開始しています. ループの中における動作を図12に示します.ループの先頭では,
|
|---|
| 図12 write_seqメソッドの解説.ループの中の動き |
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説15 |
としています.これは,tmudに書き込んでからtmuaに書き込んでいるので,上で説明したとおり,メモリ書き込みを表しています.ここではスレッドごとに,reg_addressに入っている配列Aのアドレスに,reg_dataに入っている値を書き込んでいます.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説16 |
としています.reg_strideに64が格納されているため,これはreg_addressに64を加算するという処理になります.
次に,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説17 |
としています.これはreg_dataに16を加算するという処理です.率直に考えるとadd(reg_data, reg_data, 16)と書きたくなりますが,整数の即値は-16~15しか使用できないので,$d + 16 = d - (-16)$の関係を利用しています.次に,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説18 |
としています.これは,reg_lengthから1を引き,結果が0になるかをフラグAに格納するという処理です.次の,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説19 |
では,スレッド0のフラグAが立っていない場合,つまり,reg_lengthの値がまだ0でない場合に,ループの先頭にジャンプしています.ループの最後の,
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説20 |
は,先ほど説明した3つの遅延スロットです.今回は何も行わない命令を3つ配置しました.
ループを抜けると,次の記述があります.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(1CPU,16スレッド)のソースコード解説21 |
この命令列を実行すると,QPUでのプログラム実行が終了し,CPUでのPythonプログラムの実行に戻ります.
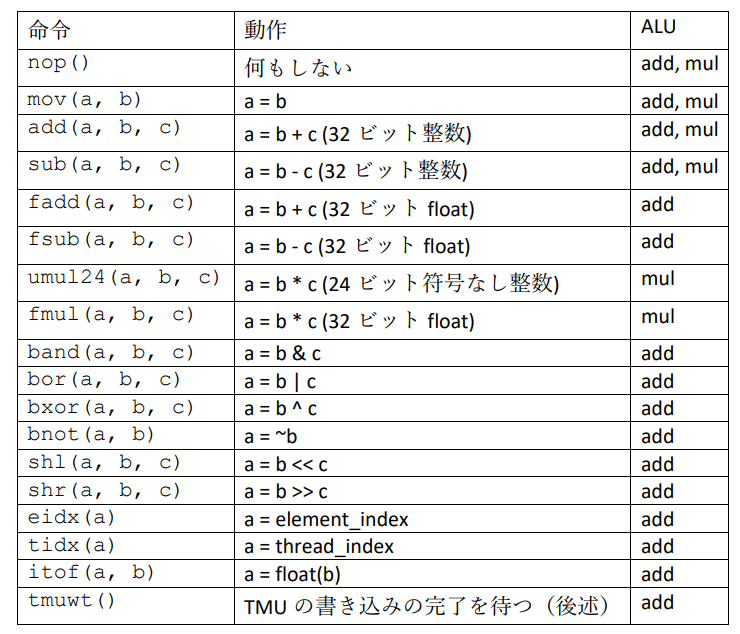
8個のQPUで同時処理
先ほど書いたプログラムは,1つのQPUだけを用いて処理を行いました.
前述のとおり,Raspberry Pi 4のVideoCore VIには,QPUが合計8つあります.理論的には,QPUを同時に多く使えば使うほど計算やメモリ入出力の処理能力が向上するはずです.そこで,8つのQPUをフルに使ってプログラムを実行してみましょう.
drv.executeメソッドには,実はthreadという,実行に使用するQPUの数を指定する隠れたパラメータがあります.何も指定しない場合はthreadには1が代入されています.8つのQPUでプログラムを実行するには,drv.execute(code, unif.addresses()[0], thread=8)とします.ここからわかるとおり,すべてのQPUで同じuniformが読まれます.QPUごとに別の動作を行いたい場合は,次の手法を用います.
QPUではtidx命令を用いてthread_indexという値を得ることができます.8つのQPUでプログラムを実行したとき,(thread_index >> 2)\& 0xf でQPUの番号(0~7)を得ることができます.以下,この値をqpu_numと表記します.
qpu_numを利用すれば,メモリを読む位置をズラすなど,QPUごとに別の処理を行わせることができます.
実際に試してみましょう.
8つのQPUを使って0~127の値を書き込んでみます.1番目のQPUで0~15,2番目のQPUで16~31,というように書き込むことを考えると,各QPUとスレッドの動作は,図13のようになります.
|
|---|
| 図13 各QPUとスレッドの動作 |
ソースコードは次のとおりです.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(8CPU) |
上のプログラムをwrite_multi.pyという名前で保存し,以下のコマンドでプログラムを実行してください.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(8CPU)を実行 |
すると,図14が出力されるはずです.先ほどと同じく,“Test passed!”と表示されていればプログラムを正常に実行できています.

|
|---|
| 図14 write_multi.pyの実行結果 |
write_multiメソッド
まず,CPUで実行されるwrite_multiメソッドの解説をします.
メモリの確保を行う
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(8CPU)のソースコード解説1 |
という箇所で,drv.allocの第一引数に (nthreads, 16)というタプルを指定しています.
これは,nthreads× 16 要素の2次元の配列を作成する,という意味です.C言語でいうと uint32_t A[nthreads][16]; です.A[i][j] にアクセスするには A[i, j],A[i][j] のメモリ・アドレスを取得するには A.addresses()[i, j] とします.
他の箇所は先ほどのwrite_seqメソッドとほとんど同じです.
qpu_write_multiメソッド
次に,QPUで実行されるqpu_write_multiメソッドの解説をします.
まず,thread_indexからQPUの番号(qpu_num)を取り出す以下の処理qpu_num = (thread_index >> 2)\& 0b1111を行なっています.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(8CPU)のソースコード解説2} |
次に,メモリに書き込むデータを準備しています.qpu_write_seq ではこの値を単にelement_indexとしていましたが,ここでは element_index + 16 * qpu_num としています.これは,1つのQPUでは16スレッドが動作するため,書き込む値をQPUごとに16ずつずらすということです.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(8CPU)のソースコード解説2 |
さらに,データを書き込むメモリ・アドレスを準備しています.qpu_write_seqではA + 4 * element_index としていましたが,ここではさらに 64 * qpu_num を加えています.これは,1つのQPUが16スレッドで16個の32ビット整数(4バイト)を書き込むからです.
|
|---|
| 長さlengthの32ビット整数の配列Aに0~length-1 の値を書き込むプログラム(8CPU)のソースコード解説3 |
上記の処理でtmud,tmuaという順で書き込んだので,結果として,tmudに書き込んだ32ビットのデータが,tmuaに書き込んだアドレスに書き込まれるという動作が行われます.最後に tmuwt 命令を発行して書き込みの完了を待ち,その後にQPUプログラムの実行を終えています.
マンデルブロ集合の計算
最後に,より実践的なプログラムをQPUで動かしてみましょう.
複素数に関する漸化式 \begin{align} z_0&=0\\ z_{n+1}&={z_n}^2+c \end{align}を考えます.
このとき,$n$→∞ で $|z_n|\leq2$ となるような複素数 $c$ の集合をマンデルブロ集合と言います.逆に,$n$=0, 1, 2,… としたときに一度でも $|z_n|>2$ となる場合は,$n$→∞ で $|z_n|$→∞ となる,つまり発散することが知られています.
図15のような画像を見たことがある方も多いでしょう.複素数 c を2次元平面に投影し,c がマンデルブロ集合に属する場合は白,属さない場合は黒で表したものです.

|
|---|
| 図15 マンデルブロ集合の作図. 引用元(https://codezine.jp/article/detail/4650) |
ここで複素数 $z_n$ を,虚数 $i=\sqrt{-1}$を用いて $z_n=x_n+iy_n$,$c$ を $c=c_x+ic_y$と表すことにします.
すると,${z_n}^2=\left( {x_n}^2-{y_n}^2 \right)+2ix_n y_n $より,先ほどの漸化式は \begin{align} x_0&=0\\ y_0&=0\\ x_{n+1}&={x_n}^2-{y_n}^2+c_x\\ y_{n+1}&=2x_n y_n+c_y \end{align}となります.
条件の選び方によって出力画像に様々なバリエーションが生まれますが,今回は以下の条件で描画を行うことにします.
- $n$=16384 までの計算を行う
- $-2 \leq x \leq 1, -1.5 \leq y \leq 1.5$ の範囲で計算を行う
- 縦1024ピクセル,横1024ピクセルの画像を描画する
- マンデルブロ集合に含まれるピクセルは白,それ以外は黒で描画する
これらの条件は以下に示すソースコード上で簡単に変更できるようにしてあるので,興味のある方は試してみてください.ソースコードではそれぞれ以下の変数名にしてあります.
- maxiter = 16384
- xmin = -2, xmax = 1, ymin = -1.5, ymax = 1.5
- height = 1024, width = 1024
CPUによるマンデルブロ集合の描画
まずはCPUの1スレッドを用いて,C言語でマンデルブロ集合を描画してみます.画像の出力にはlibstbを用いるので,以下のコマンドでインストールしておきます.
|
|---|
| 画像を出力するlibstbをインストール |
素直に実装すると以下のコードになると思います.
|
|---|
| CPUの1スレッドを使ったマンデルブロ集合の描画プログラム(C言語) |
性能計測のため,以下のコードで関数を呼び出します.
|
|---|
| CPUの1スレッドを使ったマンデルブロ集合描画プログラムの性能を計測(C言語) |
これらのソースコードは mandelbrot.c というファイル名でダウンロードできます.
マンデルブロ集合のプログラム
はじめに $dy$ と $dx$ という変数を設定しています.これはそれぞれ,$y$, $x$ 方向に 1ピクセルだけ進んだとき,$c_y$,$c_x$ をどれだけ増やせばよいかを表しています.
|
|---|
| CPUの1スレッドを使ったマンデルブロ集合の描画プログラム(C言語)のソースコード解説1 |
次に,height × width のピクセルを走査する2重ループがあります.
|
|---|
| CPUの1スレッドを使ったマンデルブロ集合の描画プログラム(C言語)のソースコード解説2 |
- ymin + dy × height = ymin + (ymax - ymin) = ymax
- xmin + dx × width = xmin + (xmax - xmin) = xmax
で辻褄が合っています(誤差を考えない場合).
さらに中には,ピクセル ($i$, $j$),座標 ($c_y$, $c_x$)がマンデルブロ集合に属するかの判定を行うループがあります.ループの回数や発散の判定は上で説明したとおりです.ピクセル値の32ビットは,上から8ビットずつ不透明度,青成分,緑成分,赤成分を表しています.例えば,0xff000000 は黒,0xff0000ff は赤,0xffffffff は白,0x7f00ff00 は半透明の緑,0x00000000 は透明を表します.
QPUが描くマンデルブロ集合
続いて,QPUを用いてマンデルブロ集合を描画します.
QPUとそのスレッドが担当するピクセルの分割は,図16のようにします.つまり,横方向をスレッドの数で,縦方向をQPUの数で分割するようにします.このため,width は16の倍数,heightは使用するQPUの数の倍数とする必要があります.
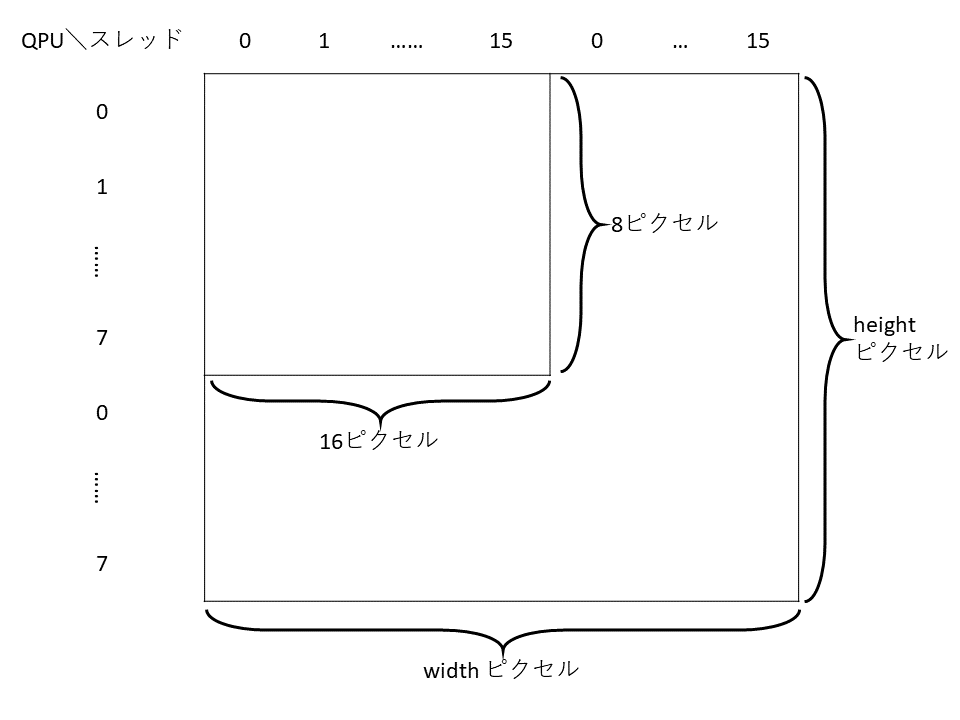
|
|---|
| 図16 QPUとそのスレッドが担当するピクセルの分割 |
以上のことを用いてプログラムを書くと,次のようになります(mandelbrot.py).
|
|---|
| CPUの1スレッドを使ったマンデルブロ集合の描画プログラム(Python言語) |
マンデルブロ集合の描画部分はCPUのコードとほとんど同じなので説明は省略します.プログラムにコメントとして何を行なっているかを書いてあるので参考にしてください.
今回のプログラムでは,qpu_mandel 関数にnqpusという引数を取り,関数内でif ... elif ... else ... で条件分岐しています.これにより実行する命令を切り替え,1つの関数で1 QPU実行にも8 QPU実行にも対応しています.
しかし,このような,@qpu デコレータの付いた関数における条件分岐はアセンブル時にCPUで行われます.そのため,条件としては定数や関数への引数しか指定することができません.例えば,if reg_i == 0 と書くことはできません.QPUでの実行時に条件分岐を行いたい場合はQPUの分岐命令を用いてください.
CPUで描くマンデルブロ集合
NEONとは,Armの上位CPUに搭載されているSIMD(Sigle Instruction, Multiple Data)命令セットです.
1命令で複数のデータに対して処理を行うことで,処理の高速化を図ります.NEONは128ビットのレジスタをもち,これを32ビット浮動小数点数×4個や64ビット整数× 2個などと分割して処理を行います.
例えば,32ビット整数の普通の加算命令と32ビット整数×4個のNEONの加算命令をどちらも1クロックで1回実行できる場合,理論的には後者のほうが4倍の性能を出すことができます.ただし,NEONの命令のレイテンシ(命令を実行して結果が返ってくるまでのサイクル数)は比較的大きいので,実際のアプリケーションできっかり4倍の性能を出すのは難しいです.
ところで,Raspberry Pi 4のCPUは,ArmのCortex-A72で,NEON命令セットに対応しています.また,4コアが搭載されています.そこで,NEON命令と複数コアを用いてマンデルブロ集合を描画してみます.
ソースコードを下に示します.
NEON命令はintrinsicsを用いてC言語から呼び出しました.詳しい動作については https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics を見てください.マルチスレッド化にはOpenMPを用いました.omp_get_num_threads()で動作しているスレッドの数,omp_get_thread_num()でスレッド番号 (0, 1, ...)を取得できます.
各スレッドの仕事の分割は,8つのQPUを用いた並列化と同じく行いました.プログラムは演算順序の入れ替えやループ・アンローリングなどの最適化技法も用いて,なるべく高速に実行できる実装を目指しました.
|
|---|
| CPU の NEON 命令セットを用いたマンデルブロ集合の描画 |
CPUとGPUの実力比較(理論値)
Raspberry Pi 4に搭載されているCortex-A72の1コアは,1.5GHzで動作し,32ビット浮動小数点数×4個の積和演算(a + b \times c つまり 2演算)を1クロックで1回実行することができます.
よって,1コアあたり 1.5GHz×8FLOP = 12GFLOP/s の理論性能があります.これが4コアあるため,CPU全体では 12GFLOP/s× 4コア = 48GFLOP/s の理論性能があります.QPUの性能と合わせて,図17にまとめます.

|
|---|
| 図17 CPUとGPUの実力比較 |
1コアまたは1個あたりの理論性能も,全体の理論性能も,CPUよりQPUのほうが低いことがわかります.では,理論ではなく実際の性能はどうでしょうか?
CPUとGPUの実力比較(実測値)
CPUのプログラムのコンパイルにはGCC 8.3.0を使用し,コンパイル・オプションは -O3 -fopenmp -mcpu=cortex-a72 -mtune=cortex-a72 -mfloat-abi=hard -mfpu=neon-vfpv4 としました.プログラムを実行したRaspberry Pi 4ではLinuxカーネルのバージョン4.19.118を使用しました.
図18にマンデルブロ集合の描画に要した時間を示します.
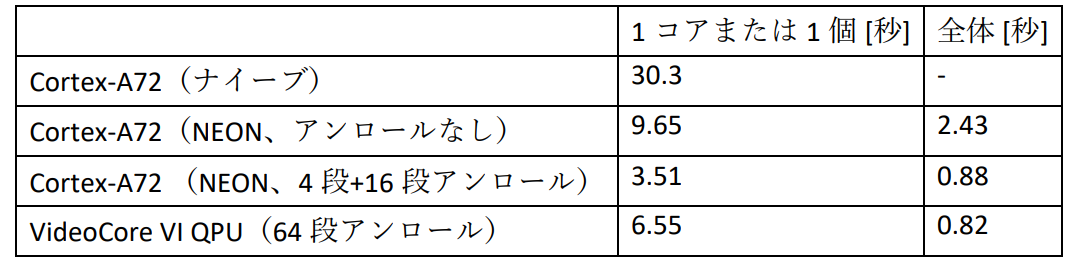
|
|---|
| 図18 マンデルブロ集合の描画に要した時間 |
まずCPUでの実行について,ナイーブ実装をNEONで書き換えると約3.14倍の性能が得られました.NEON命令では32ビット浮動小数点数×4個の計算を同時に行うので,理想的には4倍の性能が欲しいところですが,前述のように,SIMD化にはコストが伴うので,こんなものでしょう.
また,NEON実装を4コアでマルチスレッド化すると約3.97倍の性能が得られました.今回の処理はスレッド間でデータや同期の依存がないため,かなり理想に近い性能向上となっています.
さらに,NEON実装にループ・アンローリングを施すと,2.75倍の性能が得られました.NEON命令は通常の命令と比較してレイテンシが大きいことがほとんどなので,収束のチェックをまとめて行うことで,かなりの性能向上を得ることができました.
次にQPUでの実行について,8QPUでの計算は1 QPUと比較して約7.99倍高速でした.こちらもQPU間での依存がないため,理想に近い性能向上になっています.
最後に,CPUとQPUの結果を比較します.先ほど述べたように,QPUの理論性能はCPUの理論性能より低いです.にも関わらず,今回の計算においてはQPUのほうがCPUより性能が高い,という結果になりました.
ただし,CPUのプログラムも,計算の順序を変えたり,プログラムをアセンブリ言語で書き直したりすれば,さらに性能が上がるかもしれません.CPUとQPUの優位は計算内容や最適化の度合いによってまったく変わってしまうので,今回の結果はあくまで参考程度に考えてください.実際にアプリケーションを高速化する際には,計算の内容がCPUやQPUの特性とマッチするかを事前に考えるとよいでしょう.
まとめ
本記事ではRaspberry Pi 4のGPUであるQPUを用いてマンデルブロ集合を描画しました.結果として,理論性能の低いQPUのほうがCPUよりも高速に処理を行うことができました.
QPUのプログラミングは,16要素を同時に処理する点を除けばCPUとほとんど同じです.しかも,アプリケーションによってはCPUよりも高速に動作させることができます.みなさんもぜひQPUのプログラミングに親しみ,よいラズベリー・パイ・ライフを送っていただければと思います.〈杉崎 優〉
コラム2 交通法だけでなく電波法も遵守せよ
日本において特定の周波数帯の電波を発する機器を使用する場合,その機器が技適 (技術基準適合証明)を取得している必要があります.同様の規定は世界各国にあり,技適は日本版の基準を満たしているかどうかの証明書です.
また,技適の試験には総務大臣が指定する事細かな手順や大規模な試験装置・環境が必要で,かなりの費用や期間がかかります.そのため,国際的に販売される製品の中には,技適が通る前に販売が開始されたり,最悪の場合,日本で発売されなかったりする場合があります.技適の通っていない製品を日本国内で使用すると違法なので,仕方ありません.
Raspberry Pi 4は2019年の6月に発売されましたが,実はその時点では技適は通っていませんでした.そのため,筆者はCQ出版社を通じてマイクロニクス株式会社様から電波暗箱をお借りしました.電波暗箱を使うと,電子機器から発生する電波を遮断できるので,技適に通っていない機器を日本国内で使用できます.ただし,電波暗箱の遮蔽性能やその周波数帯によっては違法となってしまうため,使用前に仕様や法令をよく確認してください.py-videocore6のコミットログを見ると,Raspberry Pi 4の技適が通る前に筆者がコードを書いていて「おかしいな?」と思う方がいるかもしれませんが,電波暗箱を使って合法的に実験を行なっていますのでご安心ください.
2019年11月20日から,「技適未取得機器を用いた実験等の特例制度」が始まりました.これは技適に通っていない機器を試験的に使用するための制度です.この申請はインターネットのフォームに機器名や使用開始・終了予定日を入力し,その後郵送で書類を総務省に送付するだけで完了します.筆者は実際にこの申請を行い,2019年11月25日に認可が降りました.この制度で機器を使用できるのは180日間だけですが,以降,筆者はRaspberry Pi 4を電波暗箱から出して使用しています.
Raspberry Pi 4の技適は,2019年11月26日に通りました.この日以降に発売された,基板や外箱に技適マークの付いているRaspberry Pi 4は電波暗箱や申請なしに,日本国内で合法に使用できます.読者の皆さんがRaspberry Pi 4を購入したら,基板や外箱に技適マークが印字されているかよく確認してください.また,要請に応じて使用機器の技適マークを提示できなければ違法となる場合があるので,外箱に技適マークが印字されている場合は,その外箱を捨ててしまわないように注意してください.〈杉崎 優〉